2025-11-14
I am unreasonably excited about self-driving. It will be the first technology in many decades to visibly terraform outdoor physical spaces and way of life. Less parked cars. Less parking lots. Much greater safety for people in and out of cars. Less noise pollution. More space
我对自动驾驶感到异常兴奋。这将是几十年来第一个能够明显改变户外物理空间和生活方式的技术。更少的停车车辆。更少的停车场。车内和车外的人有更大的安全性。更少的噪音污染。更多的空间
2025-11-13
I took delivery of a beautiful new shiny HW4 Tesla Model X today, so I immediately took it out for an FSD test drive, a bit like I used to do almost daily for 5 years. Basically... I'm amazed - it drives really, really well, smooth, confident, noticeably better than what I'm used
今天我收到了一辆漂亮崭新的HW4特斯拉Model X,所以我立即带它出去进行了FSD测试驾驶,有点像我过去5年里几乎每天都会做的事情。基本上...我感到惊讶 - 它开得真的非常好,平稳、自信,明显比我习惯的要好
2025-10-21
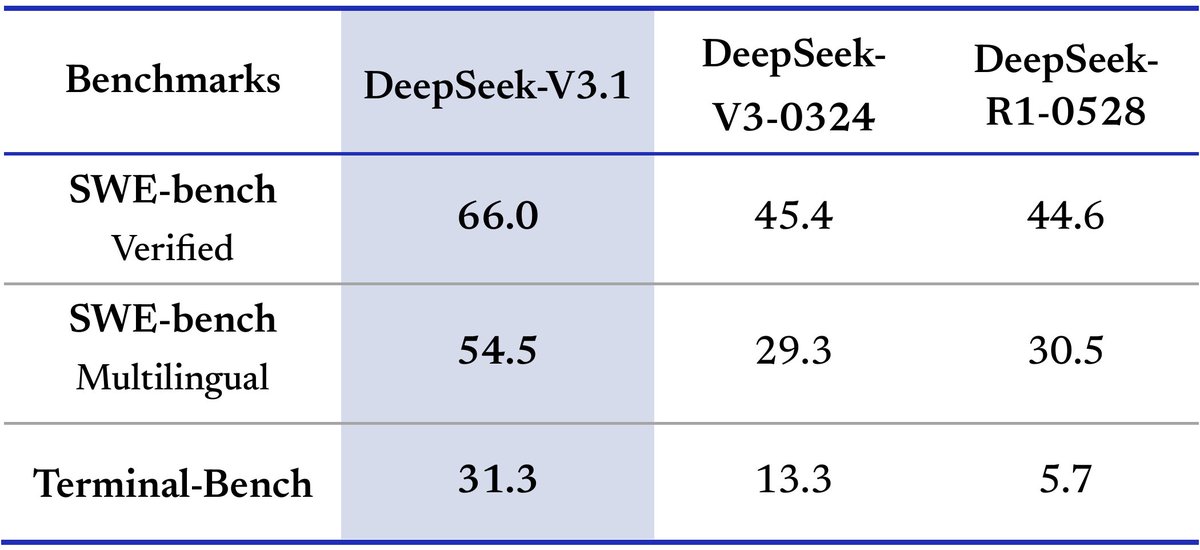
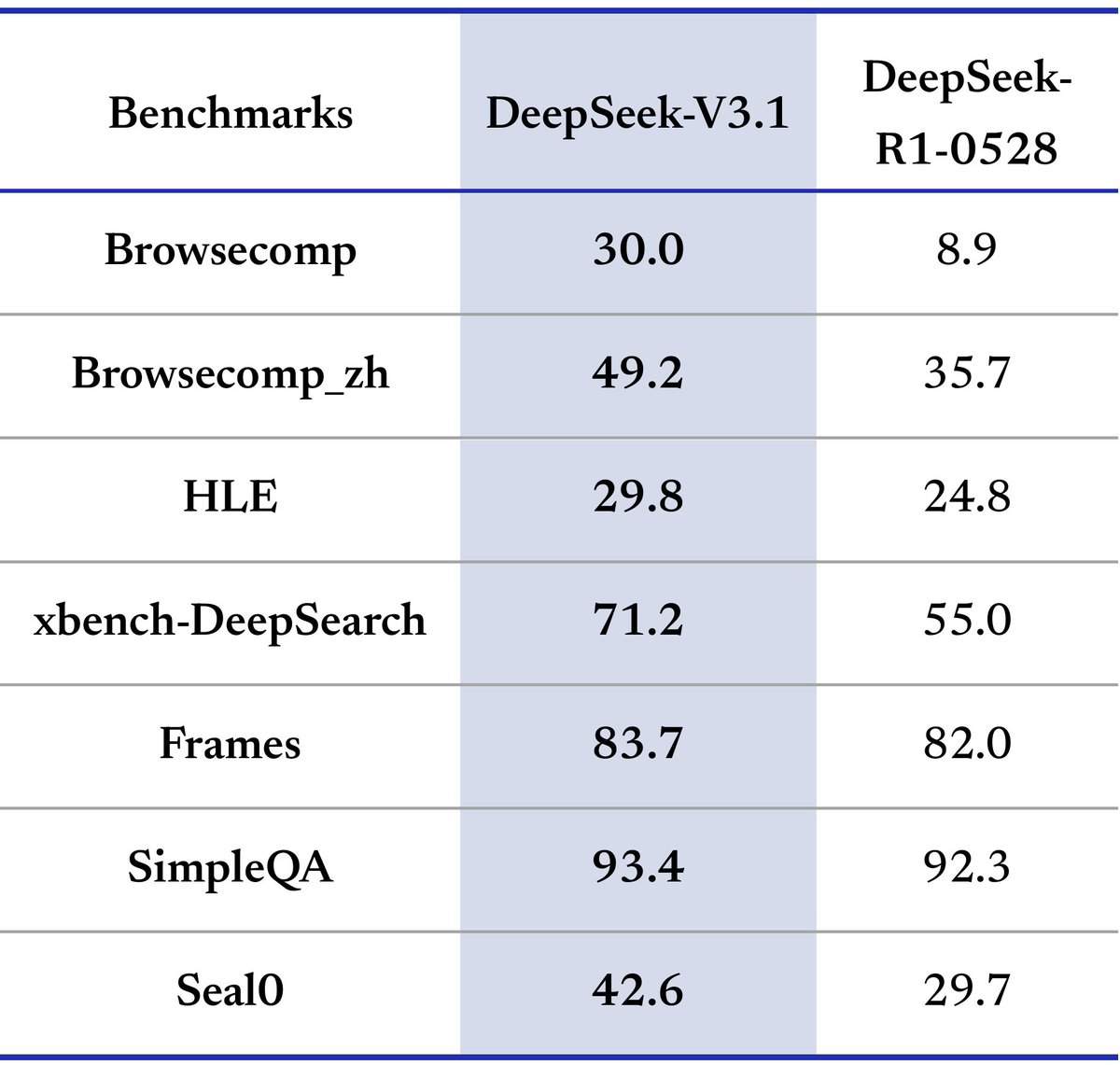
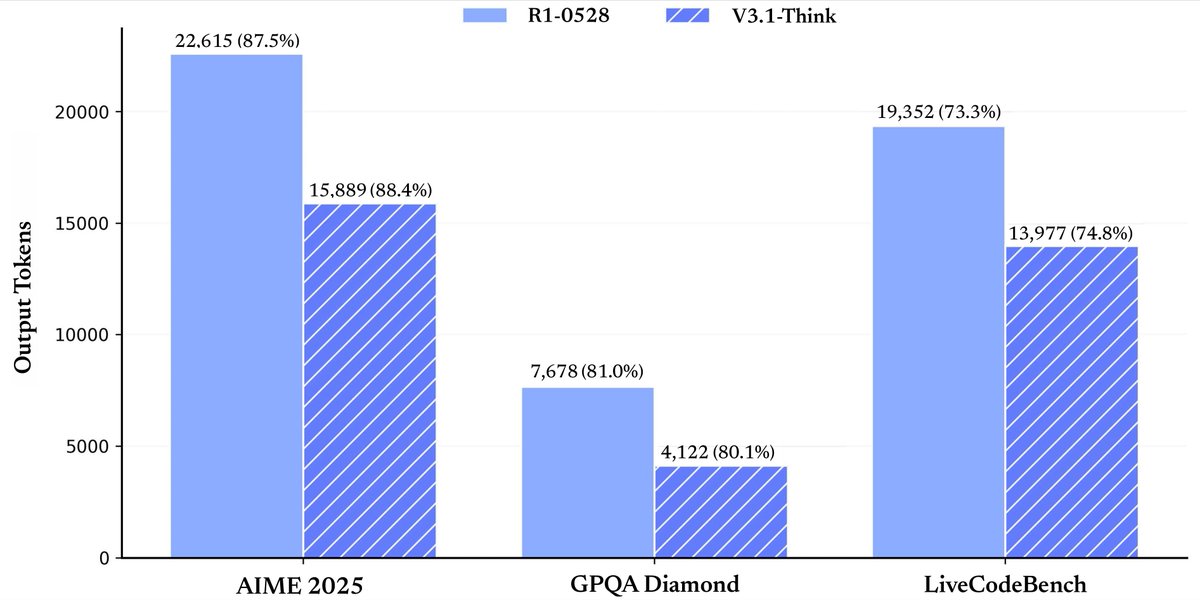
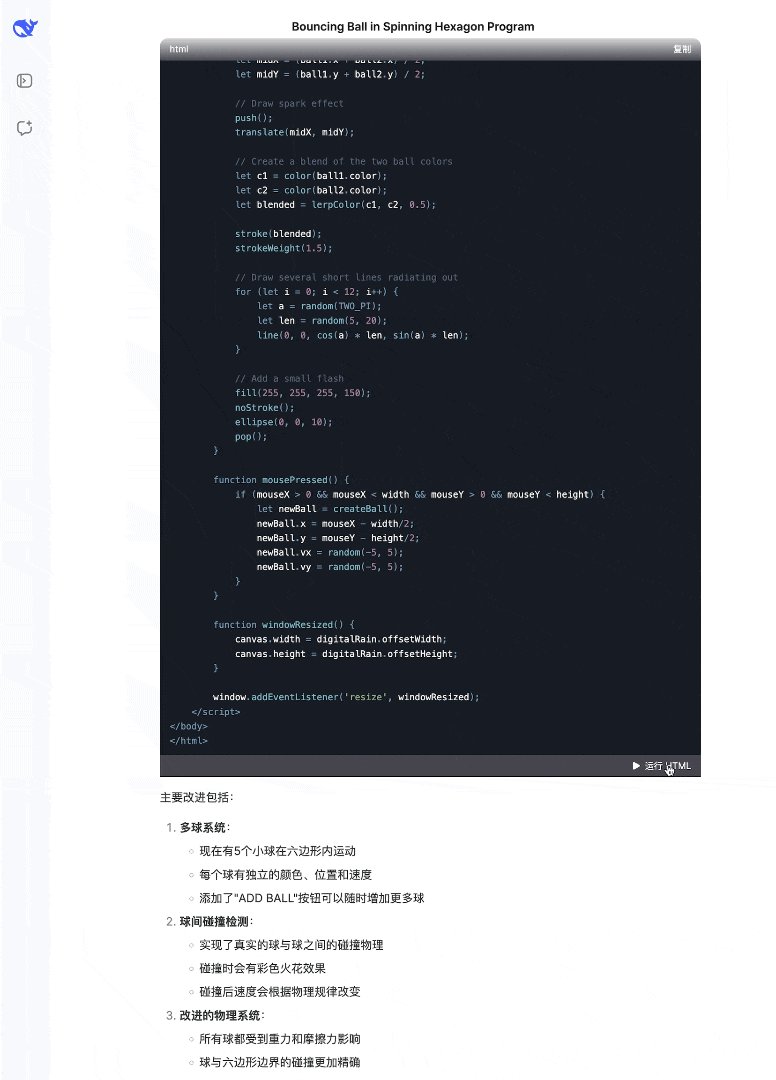
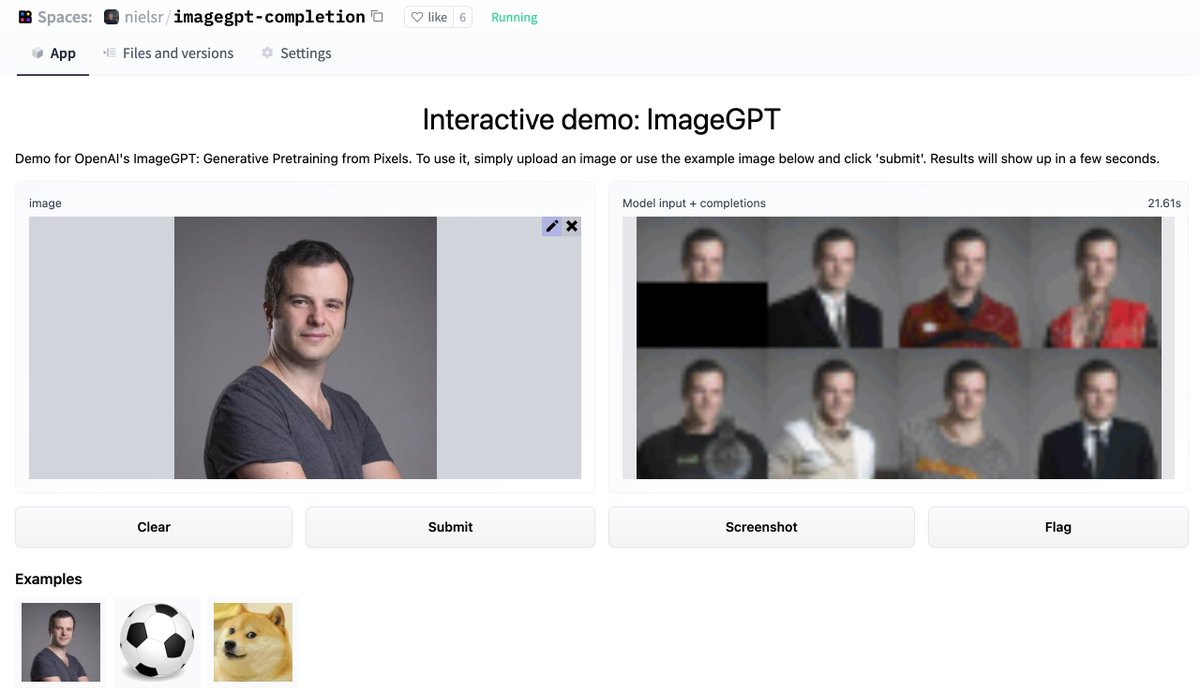
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language
vLLM @vllm_project
🚀 DeepSeek-OCR — the new frontier of OCR from
@deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
🧠 Compresses visual contexts up to 20× while keeping ht
我挺喜欢新的DeepSeek-OCR论文。这是一个很好的OCR模型(可能比dots差一点),是的,数据收集等等,但无论如何这并不重要。
2025-10-19
My pleasure to come on Dwarkesh last week, I thought the questions and conversation were really good.
I re-watched the pod just now too. First of all, yes I know, and I'm sorry that I speak so fast :). It's to my detriment because sometimes my speaking thread out-executes my
Dwarkesh Patel @dwarkesh_sp
The
@karpathy interview
0:00:00 – AGI is still a decade away
0:30:33 – LLM cognitive deficits
0:40:53 – RL is terrible
0:50:26 – How do humans learn?
1:07:13 – AGI will blend into 2% GDP growth
1:18:24 – ASI
1:33:38 – Evolution of intelligence & culture
1:43:43 - Why self https:
上周我很高兴参加Dwarkesh的节目,我认为问题和对话都非常好。
2025-10-16
TV in the 90s: you turn it on, you watch.
TV 2025:
- turn on, wait for it to load
- popup: TV wants to update, 1.5GB. No.
- scroll sideways, find prime video app or etc
- popup: now app wants to update, 500MB. No!!
- App launching... App loading…
- select account screen
- 🫠
90年代的电视:你打开它,你观看。
2025-10-14
Excited to release new repo: nanochat!
(it's among the most unhinged I've written).
Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single,
很高兴发布新的仓库:nanochat!
2025-10-02
Finally had a chance to listen through this pod with Sutton, which was interesting and amusing.
As background, Sutton's "The Bitter Lesson" has become a bit of biblical text in frontier LLM circles. Researchers routinely talk about and ask whether this or that approach or idea
Dwarkesh Patel @dwarkesh_sp
.@RichardSSutton, father of reinforcement learning, doesn’t think LLMs are bitter-lesson-pilled.
My steel man of Richard’s position: we need some new architecture to enable continual (on-the-job) learning.
And if we have continual learning, we don't need a special training http
终于有机会听完了Sutton的这个播客,很有趣且令人愉快。
2025-09-25
"AI isn't replacing radiologists" good article
Expectation: rapid progress in image recognition AI will delete radiology jobs (e.g. as famously predicted by Geoff Hinton now almost a decade ago). Reality: radiology is doing great and is growing.
There are a lot of imo naive
Deena Mousa @deenamousa
In 2016 Geoffrey Hinton said “we should stop training radiologists now" since AI would soon be better at their jobs.
He was right: models have outperformed radiologists on benchmarks for ~a decade.
Yet radiology jobs are at record highs, with an average salary of $520k.
Why? h
"AI并没有取代放射科医生"好文章
2025-09-06
I think congrats again to OpenAI for cooking with GPT-5 Pro. This is the third time I've struggled on something complex/gnarly for an hour on and off with CC, then 5 Pro goes off for 10 minutes and comes back with code that works out of the box. I had CC read the 5 Pro version
我想再次祝贺OpenAI在GPT-5 Pro上的出色表现。这是我第三次与CC断断续续地在某个复杂/棘手的问题上挣扎了一个小时,然后5 Pro花10分钟离开,回来就能直接使用的代码。我让CC阅读了5 Pro版本
2025-08-19
I get ~10 spam calls per day (various automated voicemails, "loan pre-approval" etc) and ~5 spam messages per day (usually phishing).
- I have AT&T Active Armor, all of the above still slips through.
- All of the above is always from new, unique numbers so blocking doesn't work.
我每天收到约10个垃圾电话(各种自动语音留言,"贷款预批准"等)和约5条垃圾短信(通常是钓鱼)。
2025-08-17
I am (slowly) re-reading the Tolkien legendarium (of which Lord of the Rings is a small part). The whole body of work is so incredible and there's nothing else like it... it dilutes other worlds of fiction. Wait - your story doesn't have a comprehensive history/mythology spanning
我正在(慢慢地)重读托尔金的传说集(《指环王》只是其中的一小部分)。整个作品集是如此令人难以置信,没有其他作品可以与之相比...它稀释了其他虚构世界。等等 - 你的故事没有跨越
2025-08-10
I'm noticing that due to (I think?) a lot of benchmarkmaxxing on long horizon tasks, LLMs are becoming a little too agentic by default, a little beyond my average use case.
For example in coding, the models now tend to reason for a fairly long time, they have an inclination to
我注意到,由于(我认为?)在长期任务上的大量基准测试最大化,LLMs默认情况下变得有点太智能,有点超出了我的平均用例。
2025-07-24
Love this! Supercharger, diner, … but really a kind of exhibit for the future. Plotting a road trip SF -> LA to charge Shadowfax
太喜欢这个了!超级充电站、餐厅……但实际上是未来的一种展览。正在计划从旧金山到洛杉矶的公路旅行,给Shadowfax充电
2025-07-07
Knowledge makes the world so much more beautiful.
知识让世界变得更加美丽。
2025-07-06
How to build a thriving open source community by writing code like bacteria do 🦠. Bacterial code (genomes) are:
- small (each line of code costs energy)
- modular (organized into groups of swappable operons)
- self-contained (easily "copy paste-able" via horizontal gene
如何像细菌一样编写代码,建立一个繁荣的开源社区 🦠。细菌代码(基因组)是:
2025-06-28
The race for LLM "cognitive core" - a few billion param model that maximally sacrifices encyclopedic knowledge for capability. It lives always-on and by default on every computer as the kernel of LLM personal computing.
Its features are slowly crystalizing:
- Natively multimodal
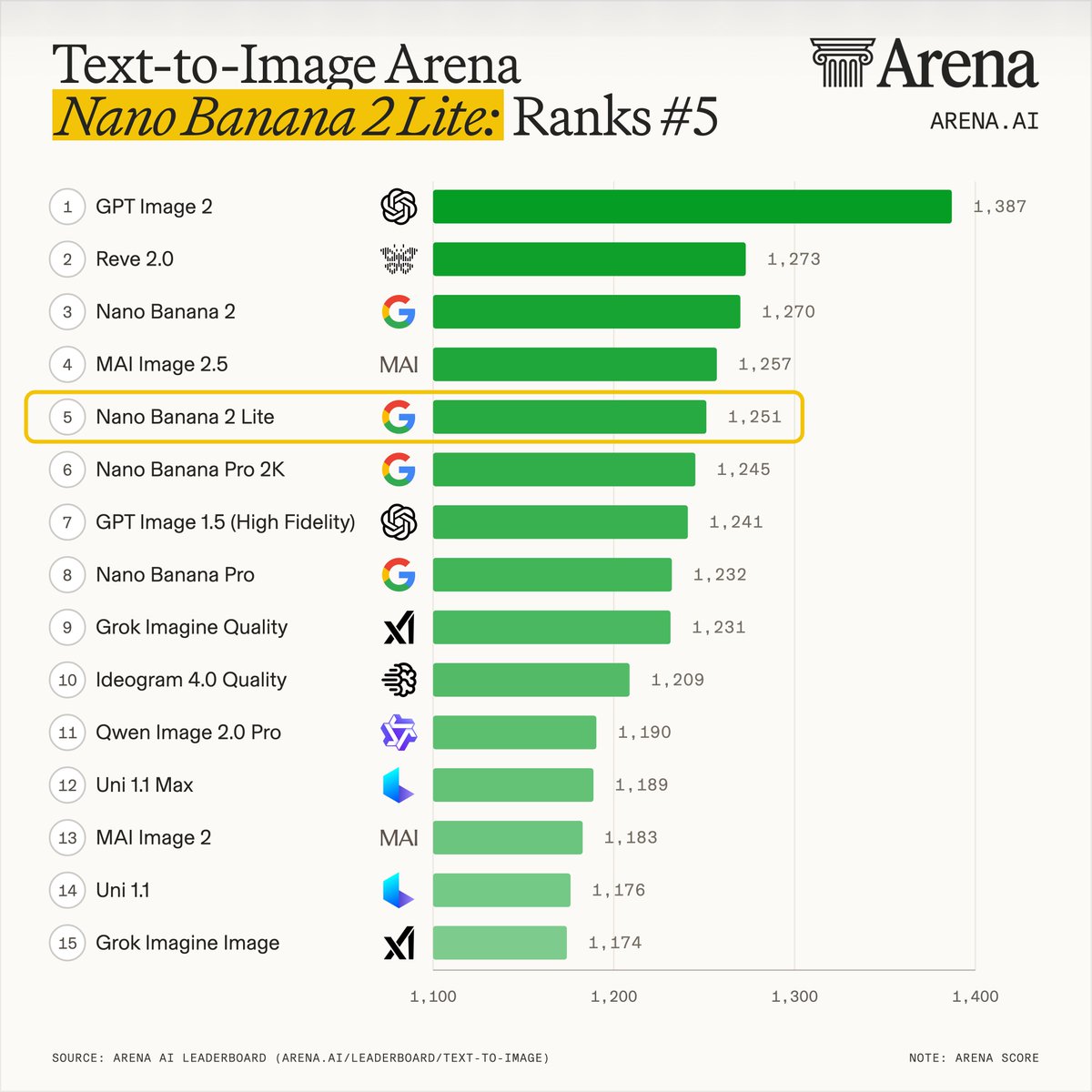
Omar Sanseviero @osanseviero
I’m so excited to announce Gemma 3n is here! 🎉
🔊Multimodal (text/audio/image/video) understanding
🤯Runs with as little as 2GB of RAM
🏆First model under 10B with
@lmarena_ai score of 1300+
Available now on
@huggingface,
@kaggle, llama.cpp,
https://t.co/CNDy479EEv, and more https
争夺LLM"认知核心"的竞赛——一个最大化牺牲百科知识以换取能力的数十亿参数模型。它始终保持开启状态,默认存在于每台计算机上,作为LLM个人计算的核心。
2025-06-26
+1 for "context engineering" over "prompt engineering".
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window
tobi lutke @tobi
I really like the term “context engineering” over prompt engineering.
It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.
支持"context engineering"(上下文工程)而非"prompt engineering"(提示工程)。
2025-06-19
Nice - my AI startup school talk is now up! Chapters:
0:00 Imo fair to say that software is changing quite fundamentally again. LLMs are a new kind of computer, and you program them *in English*. Hence I think they are well deserving of a major version upgrade in terms of
太好了 - 我的AI创业学校演讲现已上线!章节:
2025-06-19
Part 2 of this mystery. Spotted on reddit.
In my test not 100% reproducible but still quite reproducible.
🤔
Andrej Karpathy @karpathy
Not fully sure why all the LLMs sound about the same - over-using lists, delving into “multifaceted” issues, over-offering to assist further, about same length responses, etc. Not something I had predicted at first because of many independent companies doing the finetuning.
这个谜题的第二部分。在reddit上发现的。
2025-06-08
My sleep scores during recent travel were in the 90s. Now back in SF I am consistently back down to 70s, 80s.
I am increasingly convinced that this is due to traffic noise from a nearby road/intersection where I live - every ~10min, a car, truck, bus, or motorcycle with a very
我最近旅行期间的睡眠得分在90多分。现在回到旧金山,我的得分稳定回落到70多分、80多分。
2025-06-07
Making slides manually feels especially painful now that you know Cursor for slides should exist but doesn’t.
既然你知道应该存在用于幻灯片的Cursor但实际上没有,那么手动制作幻灯片就特别痛苦。
2025-06-03
An attempt to explain (current) ChatGPT versions.
I still run into many, many people who don't know that:
- o3 is the obvious best thing for important/hard things. It is a reasoning model that is much stronger than 4o and if you are using ChatGPT professionally and not using o3
尝试解释(当前)ChatGPT版本。
2025-05-11
We're missing (at least one) major paradigm for LLM learning. Not sure what to call it, possibly it has a name - system prompt learning?
Pretraining is for knowledge.
Finetuning (SL/RL) is for habitual behavior.
Both of these involve a change in parameters but a lot of human
我们缺少(至少一个)LLM学习的主要范式。不确定该称之为什么,可能它已经有了一个名称——系统提示学习?
2025-05-06
A major mistake I made in my undergrad is that I focused way too much on mathematical lens of computing - computability, decidability, asymptotic complexity etc. And too little on physical lens - energy/heat of state change, data locality, parallelism, computer architecture. The
我本科时犯的一个重大错误是我过分关注计算数学视角——可计算性、可判定性、渐近复杂度等。而对物理视角关注太少——状态变化的能量/热量、数据局部性、并行性、计算机架构。
2025-04-25
Noticing myself adopting a certain rhythm in AI-assisted coding (i.e. code I actually and professionally care about, contrast to vibe code).
1. Stuff everything relevant into context (this can take a while in big projects. If the project is small enough just stuff everything
将所有相关内容放入上下文(在大项目中这可能需要一段时间。如果项目足够小,只需放入所有内容
2025-03-27
The reality of building web apps in 2025 is that it's a bit like assembling IKEA furniture. There's no "full-stack" product with batteries included, you have to piece together and configure many individual services:
- frontend / backend (e.g. React, Next.js, APIs)
- hosting
2025年构建网络应用的现实情况有点像组装宜家家具。没有"全栈"产品即插即用,你必须组装和配置许多独立服务:
2025-03-23
I just vibe coded a whole iOS app in Swift (without having programmed in Swift before, though I learned some in the process) and now ~1 hour later it's actually running on my physical phone. It was so ez... I had my hand held through the entire process. Very cool.
我刚刚用Swift编写了一个完整的iOS应用(虽然之前没有用Swift编程过,但在过程中学了一些),大约1小时后它实际上在我的实体手机上运行了。太简单了...整个过程都有人引导。非常酷。
2025-03-19
I wrote a quick new post on "Digital Hygiene".
Basically there are some no-brainer decisions you can make in your life to dramatically improve the privacy and security of your computing and this post goes over some of them. Blog post link in the reply, but copy pasting below
我写了一篇关于"数字卫生"的快速新文章。
2025-03-13
It's 2025 and most content is still written for humans instead of LLMs. 99.9% of attention is about to be LLM attention, not human attention.
E.g. 99% of libraries still have docs that basically render to some pretty .html static pages assuming a human will click through them.
现在是2025年,但大多数内容仍然是为人类而不是为大型语言模型(LLM)编写的。99.9%的注意力即将是LLM的注意力,而不是人类的注意力。
2025-02-28
New 2h11m YouTube video: How I Use LLMs
This video continues my general audience series. The last one focused on how LLMs are trained, so I wanted to follow up with a more practical guide of the entire LLM ecosystem, including lots of examples of use in my own life.
Chapters
新的2小时11分钟YouTube视频:我如何使用大型语言模型
2025-02-27
This is interesting as a first large diffusion-based LLM.
Most of the LLMs you've been seeing are ~clones as far as the core modeling approach goes. They're all trained "autoregressively", i.e. predicting tokens from left to right. Diffusion is different - it doesn't go left to
Inception @_inception_ai
We are excited to introduce Mercury, the first commercial-grade diffusion large language model (dLLM)! dLLMs push the frontier of intelligence and speed with parallel, coarse-to-fine text generation.
https://t.co/HfjDdoSvIC作为首个基于扩散的大型语言模型,这很有趣。
2025-02-25
Agency > Intelligence
I had this intuitively wrong for decades, I think due to a pervasive cultural veneration of intelligence, various entertainment/media, obsession with IQ etc. Agency is significantly more powerful and significantly more scarce. Are you hiring for agency? Are
Garry Tan @garrytan
Intelligence is on tap now so agency is even more important
能力 > 智力
2025-02-18
I was given early access to Grok 3 earlier today, making me I think one of the first few who could run a quick vibe check.
Thinking
✅ First, Grok 3 clearly has an around state of the art thinking model ("Think" button) and did great out of the box on my Settler's of Catan
今天早些时候我获得了Grok 3的早期访问权限,让我成为我认为最早能进行快速氛围检查的人之一。
2025-02-08
Part of the reason for my 3hr general audience LLM intro video is I hope to inspire others to make equivalents in their own domains of expertise, as I’d love to watch them.
我制作3小时面向普通观众的大型语言模型介绍视频的部分原因是我希望激励其他人在他们自己的专业领域制作类似内容,因为我很乐意观看它们。
2025-02-06
New 3h31m video on YouTube:
"Deep Dive into LLMs like ChatGPT"
This is a general audience deep dive into the Large Language Model (LLM) AI technology that powers ChatGPT and related products. It is covers the full training stack of how the models are developed, along with mental
YouTube上的新视频3小时31分钟:
2025-02-03
There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper
有一种我称之为"氛围编码"的新编程方式,在这种方式中,你完全顺应氛围,拥抱指数级增长,甚至忘记代码的存在。这是可能的,因为大型语言模型(例如带有Sonnet的Cursor Composer)变得太好了。而且我只是用SuperWhisper与Composer对话
2025-01-31
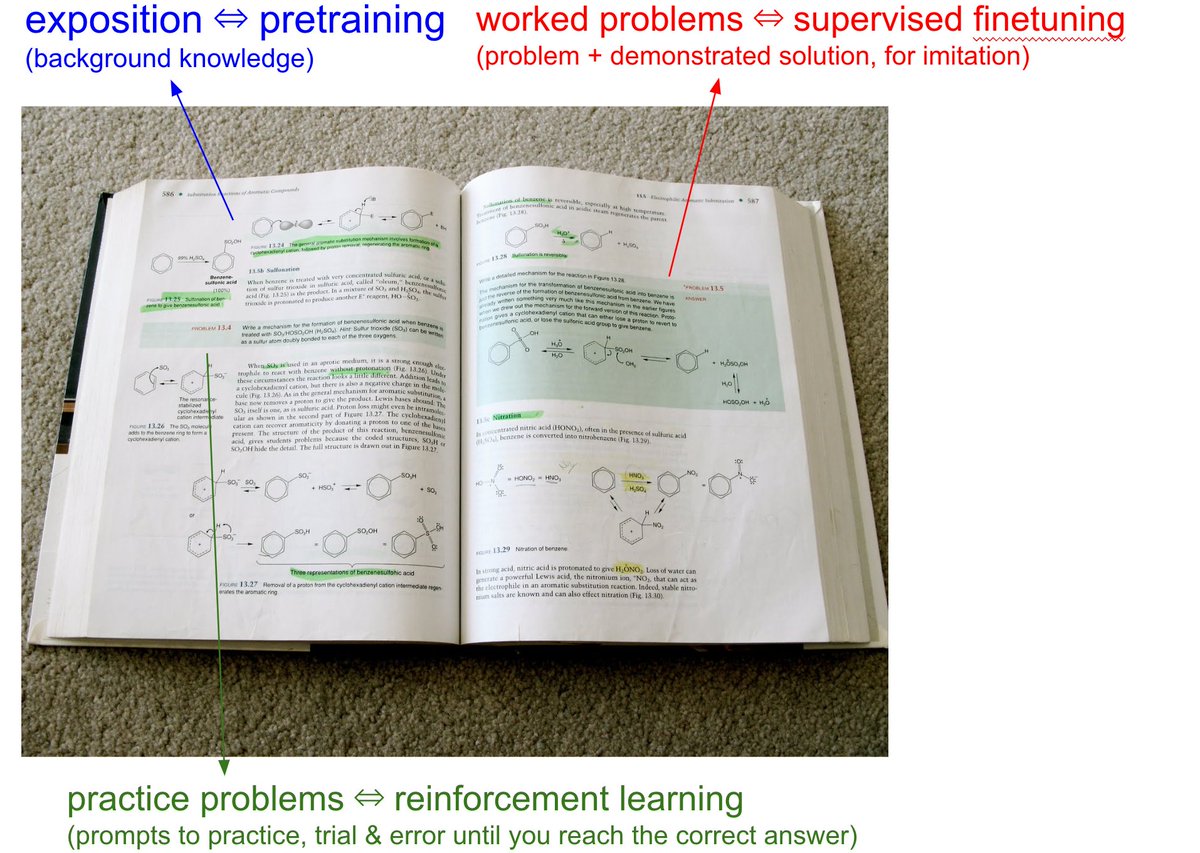
We have to take the LLMs to school.
When you open any textbook, you'll see three major types of information:
1. Background information / exposition. The meat of the textbook that explains concepts. As you attend over it, your brain is training on that data. This is equivalent
背景信息/阐述。教科书中解释概念的核心内容。当你阅读它时,你的大脑正在训练这些数据。这相当于...
2025-01-30
For friends of open source: imo the highest leverage thing you can do is help construct a high diversity of RL environments that help elicit LLM cognitive strategies. To build a gym of sorts. This is a highly parallelizable task, which favors a large community of collaborators.
对于开源的朋友们:imo你能做的最高杠杆的事情是帮助构建多样化的强化学习环境,这些环境有助于激发大语言模型的认知策略。建立某种形式的"训练场"。这是一个高度可并行化的任务,有利于大型协作社区。
2025-01-29
"Move 37" is the word-of-day - it's when an AI, trained via the trial-and-error process of reinforcement learning, discovers actions that are new, surprising, and secretly brilliant even to expert humans. It is a magical, just slightly unnerving, emergent phenomenon only
"第37步"是今日热词 - 它指的是通过强化学习的试错过程训练的AI,发现了对专家人类来说新颖、令人惊讶且秘密 brilliant 的行动。这是一种神奇的、略带不安的、仅有的涌现现象...
2025-01-28
I don't have too too much to add on top of this earlier post on V3 and I think it applies to R1 too (which is the more recent, thinking equivalent).
I will say that Deep Learning has a legendary ravenous appetite for compute, like no other algorithm that has ever been developed
Andrej Karpathy @karpathy
DeepSeek (Chinese AI co) making it look easy today with an open weights release of a frontier-grade LLM trained on a joke of a budget (2048 GPUs for 2 months, $6M).
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being
对于这篇关于V3的早期帖子,我没有太多可以补充的内容,我认为它也适用于R1(这是更近期的思维等效版本)。
2025-01-09
I still do this most days and I think it works great. My morning brain (right after 1hr exercise and 1 coffee) is quite eager to work and I go directly to the one top priority item. The energy decreases over time and with every distracting item loaded into the context window.
我大多数日子仍然这样做,而且效果很好。我早晨的大脑(在1小时锻炼和1杯咖啡之后)非常渴望工作,我会直接处理那个最高优先级的任务。能量会随着时间推移而下降,并且随着每个分散注意力的事项加载到上下文窗口中而减少。
2024-12-27
DeepSeek (Chinese AI co) making it look easy today with an open weights release of a frontier-grade LLM trained on a joke of a budget (2048 GPUs for 2 months, $6M).
For reference, this level of capability is supposed to require clusters of closer to 16K GPUs, the ones being
DeepSeek @deepseek_ai
🚀 Introducing DeepSeek-V3!
Biggest leap forward yet:
⚡ 60 tokens/second (3x faster than V2!)
💪 Enhanced capabilities
🛠 API compatibility intact
🌍 Fully open-source models & papers
🐋 1/n
https://t.co/p1dV9gJ2SdDeepSeek(中国AI公司)今天发布了一个前沿级别的大语言模型的开放权重,这个模型是在一个笑话般的预算上训练的(2048个GPU,2个月,600万美元)。
2024-12-17
AI video generation today. When I was back in school, the story of the field of computer graphics (and physically based rendering etc.) was that we will carefully study and model all the object/scene geometry, physics, rendering etc., and after 1000 PhDs and 50 SIGGRAPHs get
Agrim Gupta @agrimgupta92
"A pair of hands skillfully slicing a ripe tomato on a wooden cutting board"
#veo https://t.co/VDuxnkvIa0当前的AI视频生成。当我上学时,计算机图形学领域(以及基于物理的渲染等)的故事是,我们将仔细研究和建模所有对象/场景几何、物理、渲染等,在1000个博士学位和50个SIGGRAPH会议之后才能...
2024-12-15
The most bullish AI capability I'm looking for is not whether it's able to solve PhD grade problems. It's whether you'd hire it as a junior intern.
Not "solve this theorem" but "get your slack set up, read these onboarding docs, do this task and let's check in next week".
我最看好的AI能力不是它能否解决博士级别的问题。而是你是否会雇佣它作为初级实习生。
2024-12-09
"I love traveling the world" 😂
(I think I reference this meme a lot so)
"我爱环游世界" 😂
2024-12-09
Of ~200 books I've read, the few that stayed with me over time and I find myself often thinking back to or referring to, in ~random order:
All short stories by Ted Chiang, especially Exhalation, Division By Zero, Understand, The Story of Your Life, Liking What You See, The
在我读过的约200本书中,少数几本随着时间的推移一直留在我心中,我发现自己经常回顾或引用它们,顺序大致随机:
2024-12-02
The reality of the Turing test
图灵测试的现实
2024-11-30
People have too inflated sense of what it means to "ask an AI" about something. The AI are language models trained basically by imitation on data from human labelers. Instead of the mysticism of "asking an AI", think of it more as "asking the average data labeler" on the
人们对"向AI询问某事"的含义过于夸大。AI基本上是通过模仿人类标注者的数据进行训练的语言模型。与其将"向AI询问"神秘化,不如更多地将其视为"向普通数据标注者"询问...
2024-11-24
My Gladiator 2 review.
我的《角斗士2》影评。
2024-10-13
By chance I happened to watch this with the music of Interstellar playing in the background. Incredible. Huge 👏 to the team at SpaceX!!
偶然间我观看了这部电影,背景音乐是《星际穿越》的配乐。太不可思议了。向SpaceX团队致以巨大的👏!!
在 X 上查看 @karpathy 更多 →